Library Sort
Library Sort is a sorting algorithm that uses binary search in order to place items into the right position in a pre-sorted list.
How Library Sort works
The essence behind Library Sort is very similar to Insertion Sort: first you start with a sorted sub-array of size 1, and then you add items into this sub-list one at a time into their correct position.
The main difference is that instead of using a linear search to insert items into this array, we use binary search.
Example
Consider a half-sorted array of 10 items:
[8, 5, 1, 0, 3, 2, 4, 6, 7, 9]
The right half is sorted, so we’ll split it off.
[8, 5, 1, 0, 3][2, 4, 6, 7, 9]
Next we take the next item to add, 3, and perform binary search to find its correct place in the array:
- Start by comparing it to the 6 in the middle; it’s lower so we move left.
- Then compare it to the 2; it’s greater so we move to the right.
- Finally compare it to the 4; it’s less so we move to the left.
At this point, the gap between items has reached size 0 so we know that we’ve found the correct position. It is then inserted between the 2 and 4 like this:
[8, 5, 1, 0][2, 3, 4, 6, 7, 9]
The process is repeated for the rest of the elements.
Visualisation
TBD
Time complexity
Library Sort uses comparisons and inserts primarily, and only uses swaps to reverse the array.
Comparisons
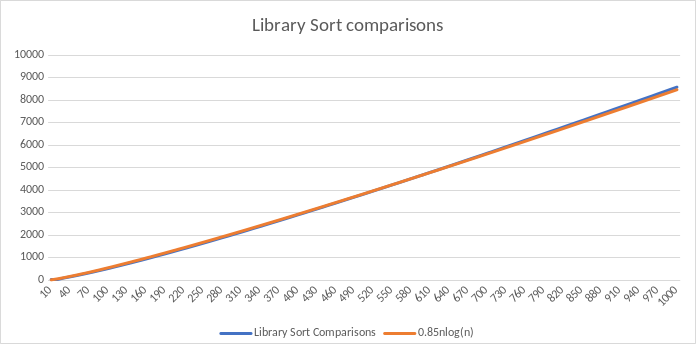
Library Sort is actually one of the most efficient algorithms for comparisons since it runs faster than O(nlog(n)).
Inserts
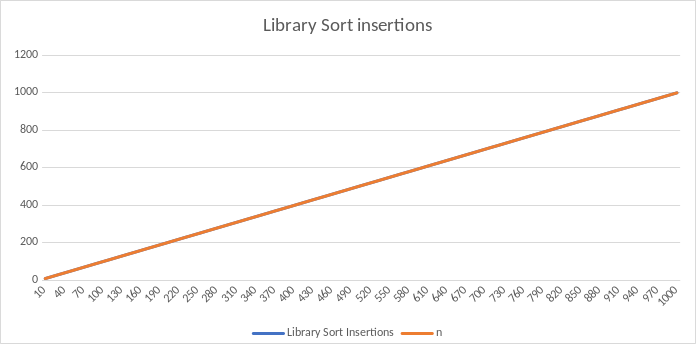
For insertions, it runs as expected. It inserts every item into the sub-array once, hence the O(n) timing.
Distribution
This is how the comparisons and swaps are distributed for this sorting algorithm of size 100 for 1,000,000 sorts.
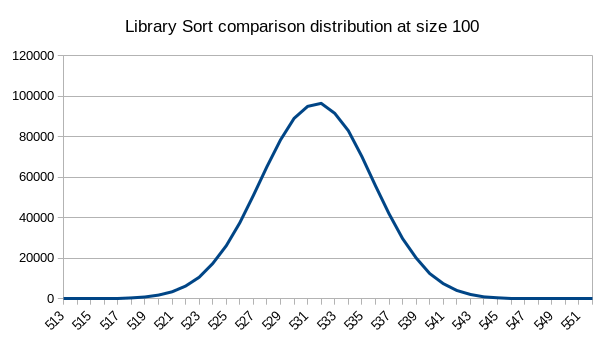
Mode: 532
Mean: 531
Std dev: 4
Max: 552
Min: 513
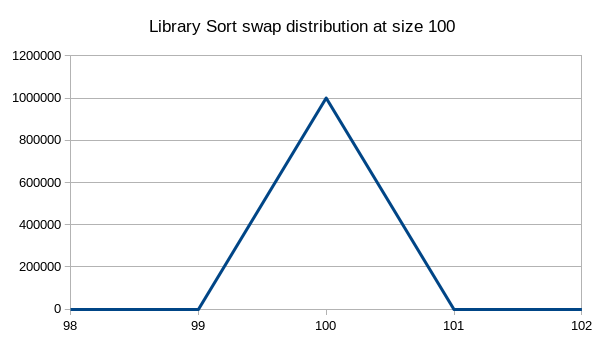
Mode: 100
Mean: 100
Std dev: 0
Max: 100
Min:100
The comparison distribution is quite interesting. It has one of the lowest standard deviations of any of the sorting algorithms I’ve seen so far. This makes the graph look incredibly smooth, with very little vertical ‘noise’ to account for.
When comparing it to its cousin, Insertion Sort, Lubrary Sort is much faster since it works on a O(nlog(n)) scale rather than a O(n2) for the average case. However, for sorting a pre-sorted list Insertion sort will be better since each element only takes one comparison, where Library Sort takes log(n) comparisons.
Insertions will always be equal to n since every item is inserted into the subarray exactly once.
C code
void library_sort(int *p, int len) {
int sublen; // Length of sorted sub-array
int start; // The start of the current sub-array being sorted
int temp; // Temp variable for the insertion
// Loop through all elements, starting from the right
for (int i=len-1; i>=0; i--) {
// Set the sub-array to start right after the current element being compared
start = i;
sublen = len-i;
// Perform a binary search on the sublist for the right place to put the new element
while (1) {
// Compare it to the midpoint
if (is_greater_than_p(&p[i], &p[start+sublen/2])) {
// It's greater, let's analyse the right-side of the subarray
start += sublen/2;
sublen -= sublen/2;
} else {
// It's lesser, let's analyse the left-side of the subarray
sublen /= 2;
}
if (!(sublen/2)) {
// It's over, let's insert the item already
temp = p[i];
memmove(&p[i], &p[i+1], (&p[start]-&p[i]) * sizeof(int));
insert(&p[start], temp);
break;
}
}
}
}



















